
|
|
Tài trợ cho PIC Vietnam |
||||||||
| Điều khiển Lý thuyết điều khiển và ứng dụng lý thuyết điều khiển trong những trường hợp thực tế |
 |
|
|
Ðiều Chỉnh | Xếp Bài |
 14-01-2006, 07:39 PM
14-01-2006, 07:39 PM
|
#1 |
|
PIC Bang chủ

Tham gia ngày: May 2005
Bài gửi: 2,631
: 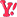  |
Bộ lọc Kalman
Ai có nhu cầu Kalman thì bay vô đây chơi... Mở ra nhưng lười viết bài quá, ai quan tâm thì F sẽ post một số tài liệu lên cho mọi người xem chơi..
F rất khôn, điều khiển thì chỉ học PID, mạch lọc thì chỉ học Kalman ...   Tài liệu tham khảo: [1] Introduction to Random Signals and Applied Kalman Filtering của Brown và Hwang: http://www.tailieuvietnam.net/download/Kalman/Brown.pdf [2] http://www.cs.unc.edu/~welch/kalman/index.html
__________________
Công ty TNHH Thương mại và Giao nhận R&P store.hn@rpc.vn - store.hcm@rpc.vn Học PIC như thế nào? thay đổi nội dung bởi: falleaf, 15-12-2007 lúc 11:52 PM. |

|

|
|
15-01-2006, 06:39 PM
|
#2 |
|
PIC Bang chủ
Tham gia ngày: May 2005
Bài gửi: 2,631
: |
Đọc một bài báo đơn giản sử dụng Indirect Kalman Filter
www.picvietnam.com/download/Kalman/PRE01.pdf Đây là một báo cáo nói trong 5 phút về một bài báo liên quan đến Kalman. Đơn giản thôi, nhưng bài báo này tổng hợp cả phương pháp UMBmark, vì vậy, phải nắm bắt thật kỹ phương pháp UMBmark thì mới hiểu được bài báo này. Điều quan trong nhất trong việc thực hiện một bộ lọc Kalman, đó là mô hình hóa được hệ thống. Vì vậy, trong bài báo cáo này, F chỉ dừng lại ở việc chỉ ra mô hình hóa của hệ thống. Từng bước, F sẽ viết nhiều hơn về cái này, từ cơ bản. Nhưng trước tiên, các bạn chỉ cần nắm, làm việc với mạch lọc Kalman, tức là tìm ra mô hình của hệ thống. Chúc vui.
__________________
Công ty TNHH Thương mại và Giao nhận R&P store.hn@rpc.vn - store.hcm@rpc.vn Học PIC như thế nào? |
|
|
|
|
22-01-2006, 01:03 AM
|
#3 |
|
PIC Bang chủ
Tham gia ngày: May 2005
Bài gửi: 2,631
: |
Chép bài sao viết lại vậy
Bộ lọc Kalman 1. Bộ lọc Kalman là gì? Đầu tiên, bộ lọc Kalman là bộ lọc do một cái ông nào đó có tên Kalman nghĩ ra, ỗng sống chết thế nào không cần biết, mặt mũi ỗng thế nào không cần hay. Chỉ cần biết ỗng chế ra một bộ lọc dùng được, nên lấy tên mình đặt cho bộ lọc. Nhưng nói vậy chứ, ai tò mò muốn biết thì vào đây coi. Cực kỳ đẹp trai. 1.1. Bộ lọc là gì? Bộ lọc là cái đồ để lọc, có nghĩa là có một thứ dơ bẩn nào đó, bỏ vào thì nó giữ lại những cái dơ và cho ra những cái sạch ở đầu bên kia. Thiệt ra thì F về nhà hỏi bà nội F làm sữa đậu nành thế nào mới biết cái bộ lọc chỉ là cái miếng vải may lại rồi cứ thế đổ nước đậu và bã đậu vào.. cuối cùng bã đậu còn lại trong cái bị còn nước đậu chảy ra ngoài, hứng, nấu, khuấy đường... rồi uống. 1.2. Bộ lọc Kalman là gì? Bộ lọc Kalman cũng là cái bịch vải của bà nội F thôi, nhưng mà ỗng không đổ bã đậu vào, mà ỗng đổ nhiễu tín hiệu vào đó, rồi có cả tín hiệu sạch, rồi đủ thứ hầm bà lằng trong đó, tóm lại là ỗng sẽ lấy ra được là tín hiệu sạch. Tuy nhiên, cũng cần phải phân biệt rằng, cái vải lọc của bà nội F thì có lọc kiểu gì thì cũng là nước đậu, đâu có lọc ra nước tinh khiết được. Thế nên, tóm lại là cái bộ lọc Kalman cũng không hơn gì cái miếng vải của bà F, nó cũng chỉ lọc ra được tín hiệu sạch, theo nghĩa không còn nhiều nhiễu, nhưng cũng chỉ là ước lượng của tín hiệu thực, chứ không phải chính xác là tín hiệu thực. Như vậy, người ta còn gọi bộ lọc Kalman là bộ lọc ước lượng, cũng vì lẽ đó. Hôm nào rảnh lại viết tiếp, làm gì chứ nấu đậu nành chán lắm, tốt hơn là đi mua một ly đậu nành đá uống vẫn tốt hơn.
__________________
Công ty TNHH Thương mại và Giao nhận R&P store.hn@rpc.vn - store.hcm@rpc.vn Học PIC như thế nào? thay đổi nội dung bởi: falleaf, 17-02-2006 lúc 10:50 PM. |
|
|
|
|
22-01-2006, 01:13 PM
|
#4 |
|
PIC Bang chủ
Tham gia ngày: May 2005
Bài gửi: 2,631
: |
Để tiện theo dõi, các bạn download tài liệu này về để tham khảo:
www.picvietnam.com/download/Kalman/Course1.pdf Phần 2, F sẽ nói lại vấn đề học bộ lọc Kalman như thế nào? Ông thầy F giảng rất hay về bộ lọc Kalman, chính vì thế, F không muốn thay đổi nhiều trong bài giảng của ông ấy, nhưng về phần tự đọc, F sẽ cung cấp thêm cho các bạn một số tài liệu cần thiết, ngoài ra, F cũng sẽ cung cấp một số bài tập và bài giải liên quan đến mạch lọc Kalman. Mục tiêu để các bạn hiểu và nắm được mạch lọc này, đến mức có thể tự đọc tiếp về nó. Những ai đã nghiên cứu và có kinh nghiệm sử dụng mạch lọc Kalman, xin giúp F một tay để bổ sung những thiếu sót trong quá trình biên soạn tài liệu này. Cách học ở đây sẽ như thế nào? Mỗi tuần, F sẽ chỉ đưa lên một vấn đề nhỏ, và đưa tài liệu kèm theo, chỉ viết lại những ý chính cần thiết. Vì các công thức toán đưa lên rất mất công, mà F lại toàn viết bằng Latex, cũng không chép lại lý thuyết khi làm nhiều, cho nên rất khó copy cho các bạn xem. Tuy nhiên, F sẽ cố gắng trình bày một cách cô đọng, nhưng đầy đủ nhất. Trong các tài liệu, cần xem chương nào, F cũng sẽ nói thật rõ chương nào cần xem. Chúc vui.
__________________
Công ty TNHH Thương mại và Giao nhận R&P store.hn@rpc.vn - store.hcm@rpc.vn Học PIC như thế nào? |
|
|
|
|
26-01-2006, 02:56 PM
|
#5 |
|
PIC Bang chủ
Tham gia ngày: May 2005
Bài gửi: 2,631
: |
2. Học bộ lọc Kalman như thế nào?
2.1. Sơ kết Chúng ta đã biết, bộ lọc chỉ đơn giản như trên, nhưng chúng ta chưa biết bộ lọc Kalman như thế nào? 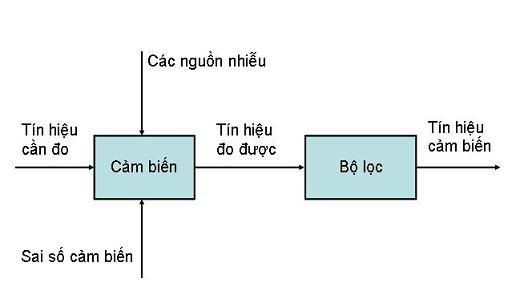 Thực ra nó cũng chỉ đơn giản là từ một tín hiệu cần đo, khi chúng ta đo, sẽ có những sai số từ cảm biến, ảnh hưởng đến tín hiệu cần đo, môi trường đo có nhiễu... Tất cả những thứ này, tổng hợp lại, sẽ cho ta một kết quả đo. Nó cũng giống như chúng ta bỏ cả nước đậu, bã đậu, và tất tần tật mọi thứ vào trong một cái túi vải để lọc. Hình ảnh sau có vẻ sẽ thân thiện với các bạn hơn? 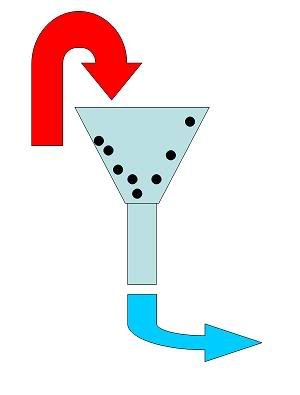 Chính vì vậy, học mạch lọc Kalman như thế nào? Đây là một câu hỏi lớn không lớn, nhỏ không nhỏ, nhưng tính quan trọng của nó dành cho những người mới học là không thể chối cãi. Chính vì vậy, F cũng đã được dạy phải học như thế nào, và ít ra thì F cũng đã học được một phần nào đó. Tuy chưa thể gọi là thấu đáo, tường tận, nhưng việc giúp các bạn có những ý tưởng cơ bản về mạch lọc Kalman, và bắt đầu nghiên cứu nó một cách phổ biến ở VN là điều F muốn làm. Một hình ảnh đơn giản được đưa ra dưới đây để trả lời cho câu hỏi trên:  Ở đây F có mấy ý thay đổi theo cách giới thiệu, đó là F cho rằng các bạn chỉ cần ghi nhận, việc học xác suất, hiểu rõ nó, sẽ quyết định tất cả khi tìm hiểu về mạch lọc Kalman. Sau đó, F mới đi giải thích vì sao xác suất lại quyết định tất cả. Nhưng các bạn hãy tạo cho mình một niềm tin trước rằng, học bộ lọc Kalman hoàn toàn không khó. Thực tế F cũng học và hiểu được nó, chưa được hoàn chỉnh lắm, nhưng nó không quá khó và quá ghê gớm. F cho rằng việc triển khai và ứng dụng mạch lọc Kalman ở VN là một việc làm đơn giản và dễ dàng. Chính vì vậy, F cung cấp thêm một cuốn sách nữa, để các bạn đọc sơ qua về xác suất. F sẽ viết rất chậm, để các bạn có thời gian đọc về xác suất. 2.2. Một thí dụ nhỏ Bây giờ F đưa ra một thí dụ sau, chúng ta lấy thước để đo chiều dài của một cây bút. Lần thứ nhất, chúng ta đo được là 10cm, lần thứ hai chúng ta đo được là 10.05cm chẳng hạn. Vậy thì nếu hỏi chiều dài cây bút là bao nhiêu? Có phải trong đầu các bạn luôn cho một giá trị ước lượng tốt nhất là 10.025cm, có phải vậy không? Điều đó đúng, nhưng căn cứ vào đâu để các bạn ước lượng như vậy? Rồi, nếu bây giờ, F lấy cây thước đo chiều dài, và được kết quả là 10.02 cm, và một bạn khác cũng lấy cây thước đo, và được chiều dài 10.07 cm. Nếu chỉ có hai kết quả này thôi, chúng ta sẽ lại ước lượng rằng chiều dài của cây thước là 10.045 cm. Đúng không nào? Nhưng thực ra, nếu F cầm cây thước đo, cứ cho rằng, bạn kia là sinh viên đi, nếu thế thì rõ ràng kết quả đo của F sẽ đáng tin cậy hơn của một bạn sinh viên??? Còn nếu người kia là ông thầy F, thì các bạn sẽ tin ông thầy F hơn, đúng không??? Vậy thì, thực chất là không thể đánh đồng được chuyện đo đạc này, mà cần có một hệ số đánh giá. Chiều dài cây thước là chiều dài = alpha * 10.02 (của F đo) + (1-alpha)*10.07 (của người kia đo) Vậy alpha sẽ là bao nhiêu? Căn cứ vào đâu để lựa chọn alpha? F đã đưa ra một số ý tưởng phác thảo, để các bạn thấy được khái niệm về ước lượng. Phần sau, chúng ta sẽ nói rõ hơn và đưa ra một ví dụ rõ hơn, và lần sau chúng ta sẽ lấy ví dụ của thầy F để hiểu rõ vấn đề hơn. Chúc các bạn ăn tết vui vẻ
__________________
Công ty TNHH Thương mại và Giao nhận R&P store.hn@rpc.vn - store.hcm@rpc.vn Học PIC như thế nào? thay đổi nội dung bởi: falleaf, 26-01-2006 lúc 02:59 PM. |
|
|
|
|
07-02-2006, 10:53 PM
|
#6 |
|
PIC Bang chủ
Tham gia ngày: May 2005
Bài gửi: 2,631
: |
Vì diễn đàn còn một số trục trặc về trình bày, cho nên F tạm thời viết không có các chức năng display tốt, các bạn thông cảm.
2.3. Một thí dụ về ước lượng Chúng ta giả sử, có một chiếc xe di chuyển với vận tốc 20m/s theo một phương x. Vị trí ban đầu của xe là 0. Khi đó, vận tốc của xe sẽ là: v_xe(t) = 20m/s + v_s(t) Trong đó, v_s(t) là nhiễu vận tốc đo. Kết quả, nếu bây giờ chúng ta cần xác định vị trí của xe sau 2 phút. Và nếu, chúng ta giải sử chúng ta chỉ quan tâm đến cảm biến đo vị trí hoặc cảm biến đo vận tốc của xe. Chúng ta sẽ chỉ ra được 2 phương pháp ước lượng như sau: a) Phương pháp 1: ^x1(0) = z1 = 0 ^x1(1) = z2 (thời điểm tiếp theo) ^x1(2) = z3 (thời điểm tiếp theo nữa) .... Đây là ước lượng vị trí của xe, chỉ nhờ vào cảm biến vị trí của xe, trong đó, zi là các giá trị vị trí xe đo được. b) Phương pháp 2: ^x2(0) = x(0) = 0 (vị trí ban đầu của xe) ^x2(1) = 0 + 20 (vị trí tiếp theo nếu giả sử xe di chuyển với vận tốc 20m/s) ^x2(2) = ^x(1) + 20 = 0 + 20 + 20 (tiếp theo nữa) ... Như vậy, cả hai phương pháp trên, cũng đều là một cách để chúng ta ước lượng vị trí của xe. Vậy áp dụng lại 2.2, chúng ta sẽ thấy rằng, nếu dùng hai phương pháp ước lượng khác nhau, chúng ta cũng sẽ có các giá trị ước lượng khác nhau. Chúng ta sẽ tin cách ước lượng nào hơn?... c) Phương pháp 3: Vậy thì, chúng ta thử xem phương pháp ước lượng thứ ba như sau: ^x3(i) = alpha*^x1(i) + (1-alpha)*^x2(i) Vậy các bạn có nhận xét gì về cách ước lượng này? Một cách chung chung (không phải là tổng quát, chỉ là khái niệm sơ khởi), nhiệm vụ của bộ lọc Kalman, chính là tìm ra hệ số alpha tối ưu để tìm ^x(t) gần đúng với x(t) nhất. Vậy nhiệm vụ của mạch lọc Kalman được phát biểu rõ hơn một chút, đó là tìm ước lượng ^x(t) gần đúng với x(t) nhất (giá trị ước lượng gần đúng với giá trị thực tế nhất) thông qua hiểu biết của chúng ta về mô hình của hệ thống. Chúc vui.
__________________
Công ty TNHH Thương mại và Giao nhận R&P store.hn@rpc.vn - store.hcm@rpc.vn Học PIC như thế nào? thay đổi nội dung bởi: falleaf, 12-02-2006 lúc 01:32 PM. |
|
|
|
|
07-02-2006, 11:20 PM
|
#7 |
|
PIC Bang chủ
Tham gia ngày: May 2005
Bài gửi: 2,631
: |
3. Bản chất của bộ lọc Kalman
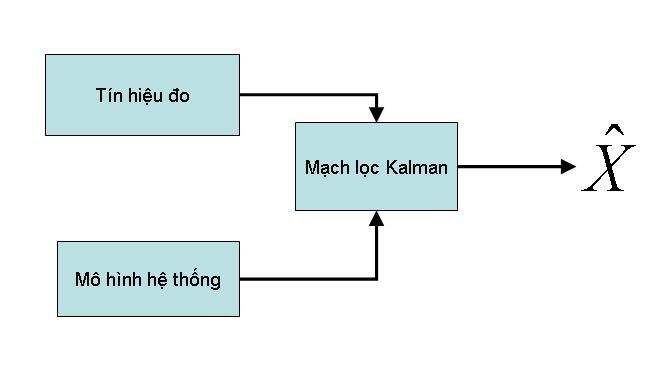 Quá trình dẫn dắt đã chỉ ra mạch lọc Kalman dùng để làm gì, như vậy, hình trên đây sẽ giúp chúng ta hiểu rõ về công việc chúng ta phải làm với mạch lọc Kalman. Trước khi học mạch lọc Kalman, F cũng muốn nói rõ với các bạn luôn, đó là mạch lọc Kalman có các công thức có sẵn rồi, và mạch lọc Kalman cũng đã bị nghiên cứu đến nát luôn rồi. Vì thế, mạch lọc Kalman không có gì quá ghê gớm để phải quan tâm. Vậy mạch lọc Kalman khó ở chỗ nào? Tín hiệu đo được thì dễ rồi, chúng ta cứ xách cảm biến ra cắm ở đâu là chúng ta đo được ở đó. Nhìn hình trên, chúng ta sẽ thấy rõ ràng rằng mạch có 4 khối, Khối Kalman thì các bạn cứ tin F là không khó, khối ^X là kết quả tính toán của mạch lọc Kalman, khối tín hiệu đo thì cắm là đo.. vậy, thực chất mạch lọc Kalman khó nhất ở phần mô hình hoá hệ thống. Mô hình hoá hệ thống gồm những gì, như thế nào, chúng ta sẽ đề cập sau. Nhưng điều vừa nói trên, một lần nữa chứng tỏ cho cái hình của F đã post phía trên: Phần mạch lọc Kalman không hề khó khăn. Vậy còn phần xác suất ngẫu nhiên vì sao lại khó? Bởi vì bản thân nó khó! F học xác suất ngẫu nhiên thấy khó! Thầy F học xác suất ngẫu nhiên cũng thấy khó! Ba mẹ F là giáo viên toán DH SP cũng thấy xác suất là khó! Còn bạn?... Ngoài ra, cũng nói sơ thêm, đó là việc mô hình hoá hệ thống, có liên quan đến việc mô hình hoá các tín hiệu nhiễu, và nhiễu quá trình đo. Mà các nhiễu này là các giá trị ngẫu nhiên. Chính vì vậy, từ đây cũng gợi cho các bạn một chút liên tưởng rằng cái khó nhất nằm trong cái khó nhất của việc học Kalman, đó là mô hình hệ thống. Hy vọng là chúng ta sẽ có thể hiểu được nó phần nào qua các bài viết sắp tới, nhưng việc trang bị cho mình kiến thức về xác suất vào thời điểm này để chuẩn bị nghiên cứu về Kalman là một việc làm vô cùng thiết thực. Vậy thì, các bạn, chúng ta cùng chuẩn bị nhé. Trong thời gian chờ đợi diễn đàn được hoàn thiện về các công cụ làm việc, các bạn có thể nghiên cứu sơ qua tài liệu sau đây để hiểu thêm phần nào về những gì chúng ta sẽ đi. Tài liệu này hướng dẫn sử dụng matlab để làm việc với bộ lọc Kalman, nhưng chương 1 của nó, giới thiệu khá kỹ về lịch sử các bộ lọc, về lý thuyết xác suất, chương 2 của nó nói về các mô hình hệ thống, chương 3 của nó nói về tiến trình ngẫu nhiên... 3 Chương đầu này là 3 chương rất cần thiết cho các bạn để bắt đầu học về bộ lọc Kalman. Trong quá trình học về bộ lọc Kalman, chúng ta sẽ cùng tham khảo sách và tài liệu với nhau để có thể trao đổi thảo luận được tốt hơn. http://www.picvietnam.com/download/K...lab_Kalman.pdf Chúc vui.
__________________
Công ty TNHH Thương mại và Giao nhận R&P store.hn@rpc.vn - store.hcm@rpc.vn Học PIC như thế nào? thay đổi nội dung bởi: falleaf, 12-02-2006 lúc 01:35 PM. |
|
|
|
|
11-02-2006, 07:02 PM
|
#8 |
|
PIC Bang chủ
Tham gia ngày: May 2005
Bài gửi: 2,631
: |
Các tiến trình ngẫu nhiên
4. Các tiến trình ngẫu nhiên
Phải nói trước rằng, đây là một phần không dễ nhai, và cũng không phải là quá khó nhai. F nói về phần này, dựa trên việc các bạn đã được học về xác suất thống kê, như vậy, ít nhất các bạn phải là sinh viên năm thứ 3 trở lên, thì các bạn mới nên theo dõi tiếp. Vì sao F không nói vấn đề này ngay từ đầu? Bởi vì thực ra, theo F nghĩ, mọi thứ không khó lắm nếu các bạn đã có khả năng. Những người nào học năm nhất về xác suất thống kê tốt, học toán tốt, thì có lẽ cũng đủ khả năng tìm hiểu đến phần này. Đối với F, một kiến thức mới, khi đã có cơ sở nền của 2 năm đại cương vững chắc, thì bất kỳ ai cũng có thể học được dễ dàng. Bởi vậy, F chỉ bảo là nên là sinh viên năm 3 trở lên, chứ F không hạn chế các bạn sinh viên năm nhất năm hai. Các bạn cứ thẳng tiến học cơ bản, năm sau các bạn quay lại đây thì diễn đàn vẫn còn đó, có khi bài học lại càng được sửa chữa tốt hơn. Đây là lời nói đầu cho phần này vậy. Nó có nghĩa là, F không phải là giáo viên xác suất thống kê, cho nên viết ra cũng chỉ thật đơn giản và mang tính khái niệm, nếu có gì sai sót, thì mong mọi người cùng giúp F bổ sung và sửa chữa. 4.1. Động lực để học các tiến trình ngẫu nhiên: 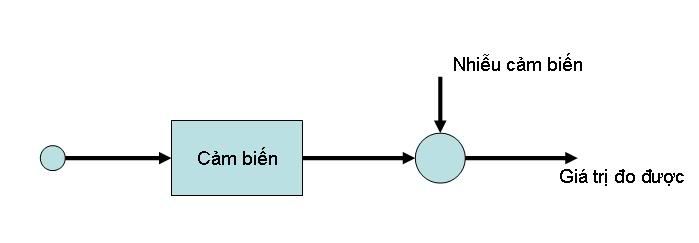 Các bạn quan sát hình trên, sẽ thấy rằng tín hiệu đo được thực tế là bị ảnh hưởng do các tác động của nhiễu. Bản thân tín hiệu trước khi vào cảm biến cũng có các ảnh hưởng của nhiễu. Mà nhiễu là các quá trình ngẫu nhiên. Vì vậy, chúng ta phải học các quá trình ngẫu nhiên. 4.2. Biến ngẫu nhiên (random variable): Bây giờ, chúng ta xem một thí dụ như sau: Trong một cái hộp kín, có 4 quả bóng A, B, C, D. Chúng ta tìm xác suất để khi bốc một lần thì được quả bóng A, hoặc bóng B? Dễ dàng thấy là xác suất bốc được bóng A, hoặc B là 2/4. Nhưng ở đây F không đề cập đến vấn đề này. Vấn đề chúng ta đề cập, đó là: P[bốc A hoặc B] = ? Thay vì viết như vậy, thì chúng ta có thể ký hiệu lại như thế này có được không? "A" -> 1 "B" -> 2 "C" -> 3 "D" -> 4 Chẳng qua chỉ là việc gán các số đại diện cho các chữ cái mà thôi, việc này không ảnh hưởng gì. Nhưng nếu bây giờ, chúng ta viết lại thế này, các bạn thấy thế nào? P[X=1 or X =2] = ? Phải chăng cách viết này đơn giản và dễ hiểu hơn? Khi viết như thế này, chúng ta gọi X là biến ngẫu nhiên. Ở đây F không nêu định nghĩa cụ thể biến ngẫu nhiên là gì, trong tài liệu "Lý thuyết Xác suất và thống kê toán học" - nhóm tác giả Trần Tuấn Điệp, Lý Hoàng Tú có nói rất rõ. Đây là giáo trình chính thức của chương trình PFIEV khi học về xác suất thống kê, và F thấy rằng tài liệu này hay hơn so với rất nhiều tài liệu về xác suất thống kê khác mà F đã được đọc (F đọc rất ít). F lại tiếp tục để thời gian, để các bạn đọc sơ lại về xác suất thống kê. Lần tới, chúng ta sẽ nói về các hàm phân bố xác suất, hàm mật độ xác suất, điểm qua một vài phân bố thông dụng, về trung bình, variance, về các tính chất độc lập, covariance... Đó là những khái niệm rất quan trọng trong xác suất. Mong các bạn chuẩn bị đọc trước để khi F viết tiếp chúng ta đỡ mất thời gian. Chúc vui.
__________________
Công ty TNHH Thương mại và Giao nhận R&P store.hn@rpc.vn - store.hcm@rpc.vn Học PIC như thế nào? thay đổi nội dung bởi: falleaf, 12-02-2006 lúc 01:35 PM. |
|
|
|
|
15-02-2006, 10:45 PM
|
#9 |
|
PIC Bang chủ
Tham gia ngày: May 2005
Bài gửi: 2,631
: |
Các khái niệm về xác suất
4.3. Hàm phân bố xác suất
Gọi hàm phân bố xác suất là F_X(theta), thì hàm phân bố xác suất được định nghĩa như sau: F_X(theta) = Prob[X<= theta] (ký hiệu <= : nhỏ hơn hoặc bằng) Để tiện theo dõi về sau, tôi sẽ sử dụng cách viết bằng latex giả. Bởi vì một số bạn không biết latex, cho nên tôi sẽ viết mã giả latex bằng tiếng Việt. Vd: tôi sẽ viết \nhbằng, thì có nghĩa là nhỏ hơn hoặc bằng. Và từ đây tôi sẽ giúp các bạn làm quen với kiểu viết latex, xem ra cũng hay hay. Các bạn lưu ý, trong latex sử dụng ký tự \ để bắt đầu một lệnh hoặc một ký tự đặc biệt nào đó. Vì vậy, nếu viết theta, thì nó sẽ hiện ra chứ theta. Nhưng nếu viết \theta thì nó sẽ hiện ra ký tự "theta" trong toán học. Chúng ta quay lại vấn đề hàm phân bố xác suất. Nhắc lại bài toán lần trước với 4 quả bóng A, B, C, D, và biến ngẫu nhiên X. Vậy F_X(2) bằng bao nhiêu? F_X(2) = Prob[X \nhbằng 2] = Prob[X=1 hoặc X=2] = Prob[Lấy được bóng A hoặc bóng B] = 1/2 Như vậy trong công thức này đã thể hiện hết các khái niệm từ đầu đến giờ chúng ta học phải không nhỉ. Vậy trong trường hợp liên tục thì sao? Giả sử xét một cây bút đặt trên mặt bàn, hệ quy chiếu là góc bàn và các cạnh bàn. Biến ngẫu nhiên \alpha là góc của cây bút theo chiều từ đuôi bút đến ngòi bút so với cạnh ngang của bàn. Chúng ta thấy rõ ràng rằng. 0 \nhbằng \alpha < 2*Pi Vậy F_alpha(Pi/4) = ? F để cho các bạn tự trả lời câu hỏi này. Chúng ta sẽ thấy rằng, với biến ngẫu nhiên liên tục hay rời rạc, hoàn toàn nó không phải là vấn đề với định nghĩa này. 4.4. Hàm mật độ xác suất Định nghĩa: f_X(\theta) là đạo hàm của hàm phân bố xác suất theo \theta, hay có thể viết f_X(\theta) = dF_X(\theta) / d(\theta) ~ Prob[X=\theta] Các bạn có thể chứng minh dấu ~ này được không? và chứng minh f_X(\theta) \thuộc [0;1]? Khi nào có thời gian vẽ hình, F sẽ đưa các hình ảnh lên cho các bạn xem. Thực ra, F rất băn khoăn khi chỉ giới hạn nói đến đây thôi có được không? Bởi vì muốn giải thích thật rõ lắm, nhưng nếu giải thích rõ thì sẽ rất mất nhiều thời gian. Chính vì vậy, thôi thì F cứ để nó đơn giản, chỉ là khái niệm, và các bạn chịu khó đọc sách về phần này. F sẽ đi thật chậm thôi. Học xác suất thống kê, quan trọng nhất là hiểu được ý nghĩa vật lý của nó, thì khi đó nói đến vấn đề gì, khái niệm gì, chúng ta hình dung ra ngay. F tránh dùng thời gian của mình để phân tích những điểm này, vì bây giờ đơn giản, phân tích ý nghĩa vật lý còn dễ, sau đến lúc khó lên, chính F cũng phải hình dung phức tạp. Lúc đó giải thích ra không được tốt cho mọi ngừơi. Mà như vậy, thì các bài viết nó thiếu tính nhất quán. F cũng tránh viết giải thích, bởi vì kiểu giải thích của F về xác suất thống kê, và hiểu về nó, nhiều người bạn của F cũng nghĩ rằng F suy nghĩ quá phức tạp, trong khi với F cái phức tạp đó lại quá đơn giản theo cách nghĩ của F... Tóm lại, nếu các bạn quyết định theo khoá học này, F nghĩ các bạn nên cố gắng dành thời gian để trao đổi thêm với nhau, và đọc sách để có thể hiểu được những vấn đề F nói một cách quá vắn tắt như thế này. Chúc vui.
__________________
Công ty TNHH Thương mại và Giao nhận R&P store.hn@rpc.vn - store.hcm@rpc.vn Học PIC như thế nào? |
|
|
|
|
09-03-2006, 07:30 PM
|
#10 |
|
PIC Bang chủ
Tham gia ngày: May 2005
Bài gửi: 2,631
: |
4.5. Phân bố đơn vị
Phần này chẳng có gì đặc biệt, các bạn đọc thêm tài liệu ở các sách như cuốn F đã giới thiệu 4.6. Phân bố Gauss và phân bố chuẩn Đây là vấn đề cần nhắc lại, nhưng vị nhắc cái đoạn này thì nó mất thời gian vẽ lại hình, cho nên F tạm thời không vẽ lại hình, F chỉ đưa ra lại công thức để nhắc lại thôi. Nếu có bạn nào cũng tham gia đọc theo tài liệu này, mong các bạn dành thời gian viết một vài điều về phân bố Gauss ở đây dùm F cái. f_X(x) = \frac{1}{sqrt{2*\pi}*\sigma}exp(-\frac{1}{2\sigma^2}(x-m_x)^2) Trong đó ký hiệu \frac{tử số}{mẫu số} = tử số / mẫu số 4.7. Trung bình E(X) = \bar X (X gạch trên đầu) =~ (dấu bằng hình thức) \int_{-\inf}^{+\inf}{x*f_X(x)dx} trong đó \inf = dấu vô cùng, đây là tích phân từ trừ vô cùng đến cộng vô cùng của tích x*f_X(x) Bây giờ, chúng ta xem một thí dụ sau, trong một cái hộp kín, có 2 trái banh, tìm trung bình của số lần bốc được trái banh A. Như vậy nếu chúng ta bốc trái banh ra 100 lần, có phải là chúng ta sẽ có E = 1/100 (X(1) + X(2) + ... X(100)) Trong đó X(i) = 1 nếu như bốc được banh A, và X(i) = 0 nếu bốc được banh B. Điều này không có gì lạ. Nhưng với quy luật ngẫu nhiên vừa rồi, thì có phải nếu chúng ta bốc 1000 lần, 100000000000...0000 lần, thì kết quả E sẽ tiến gần đến 1/2 phải vậy không? Như vậy, có nghĩa là cái dấu =~ (bằng hình thức) ở công thức trên nói với chúng ta rằng, nếu như số lần lấy mẫu tiến ra vô cùng, thì xác suất mới có giá trị đúng. Và F có một cái câu rất hay nói ngoài miệng khi quyết định một cái chuyện gì đó rằng: "Xác suất chỉ có ý nghĩa khi nó tiến ra vô cùng" để khẳng định rằng, mọi việc F làm ngày hôm nay đều đúng, bởi vì rằng khi quyết định làm gì, chúng ta chỉ có thể quyết định một lần. Chỉ khi nào nói rằng quyết định của chúng ta là đúng hay sai khi chúng ta có thể quyết định nhiều lần và quan sát được nó. Nhưng thời gian không cho phép quyết định được lặp lại, cho nên, nếu như đã có ý quyết định, thì hãy tin rằng mình quyết định đúng, bởi vì quyết định một lần, không bao giờ có khái niệm đúng hay là sai... Hơi triết lý một chút, nhưng chúng ta tiếp tục vấn đề. Chứng mình trung bình E[X] của phân phối chuẩn -1<= X <=1 là bằng 0 Chứng minh như sau: E[X] = \int_{-1}^1{x*f_X(x)dx} = \int_{-1}^1{x*1/2dx} =1/2*(1/2*x^2)|-1..1 = 0 Oki, như vậy, để bữa nào F vẽ cái hình phân bố chuẩn hay Gaussian lại cho các bạn xem. Thì các bạn sẽ thấy nó đối xứng, và nếu như nó đối xứng qua điểm 0 thì trung bình của nó phải là 0. Oki, tạm dừng ở đây, các bạn về đọc tiếp nội dung của xác suất thống kê nhé... Thiệt tình phần này nếu viết thì dài, mà không viết thì không được, nên chỉ lướt lướt qua những điểm cần ôn và chú ý, chứ không thể đi hết được. Chúc vui.
__________________
Công ty TNHH Thương mại và Giao nhận R&P store.hn@rpc.vn - store.hcm@rpc.vn Học PIC như thế nào? |
|
|
|
|
22-03-2006, 01:24 PM
|
#11 |
|
PIC Bang chủ
Tham gia ngày: May 2005
Bài gửi: 2,631
: |
4.8. Variance
Var X = E[(X-E[X])^2] = E[X^2 - 2X*E[X] + E[X]^2] = E[X^2] - 2E[X*E[X]] + E[E[X]^2] Vì E(X) là hằng số, cho nên ta có thể rút ra ngoài hàm trung bình, và chúng ta có: Var X = E[X^2] - E[X]^2 Lại tạm dừng ở đây, các bạn tiếp tục đọc thêm về phần Variance này trong cuốn sách mà F đã giới thiệu "Lý thuyết xác suất và thống kê toán học" - Trần Tuấn Điệp & Lý Hoàng Tú Xin nhắc lại đây là cuốn sách rất rất hay về xác suất thống kê ở Việt Nam mà F được biết đến. Các cuốn sách khác F cũng có xem qua bằng tiếng Việt, nhưng không thấy hài lòng cho lắm. Chúc vui.
__________________
Công ty TNHH Thương mại và Giao nhận R&P store.hn@rpc.vn - store.hcm@rpc.vn Học PIC như thế nào? |
|
|
|
|
22-03-2006, 01:38 PM
|
#12 |
|
PIC Bang chủ
Tham gia ngày: May 2005
Bài gửi: 2,631
: |
Bài tập 1:
Cho X là một biến ngẫn nhiên có phân bố đơn vị, và X nằm trong đoạn [0;1]. Tìm trung bình và Variance của X? Đây là một bài tập rất đơn giản để các bạn hiểu rõ về trung bình và variance. Các bài tập tương tự có trong các sách mà F đã đề cập, vì vậy các bạn cố gắng làm thật nhiều bài tập để nắm rõ những khái niệm xác suất thống kê này. Khi chúng ta đi tới phần mạch lọc, sẽ rất khó khăn nếu các bạn không nắm rõ được những khái niệm này. Một mặt vì F không có sách tiếng Việt, nên cũng hơi khó trình bày vì không còn nhớ từ ngữ chính xác bằng tiếng Việt, hơn nữa việc giảng về xác suất thống kê F cũng không có nhiều kinh nghiệm. Để tìm hiểu về xác suất thống kê, có lẽ các bạn ở BK HCM nên xin học một lớp của thầy ThS. Cao Hào Thi (khoa Quản Lý Công Nghiệp), bất kể là thỉnh giảng hay có lớp chính thức... F không nắm thông tin này, nhưng có lẽ F được học với thầy 1 môn Xác suất thống kê, hồi quy và ra quyết định bằng phương pháp định lượng.. đây là một trong những môn học hay nhất mà F được học tại BK HCM. Đó là một điều may mắn lớn. Thầy Cao Hào Thi có dịch lại cuốn sách xác suất thống kê dùng trong kinh tế, một cuốn sách khá dày, và các sinh viên PFIEV tại BK HCM có photo lại để học, phải nói cuốn sách này là một cuốn sách rất rất hay. Các bạn cố gắng tìm đọc và tham khảo. Chúc vui.
__________________
Công ty TNHH Thương mại và Giao nhận R&P store.hn@rpc.vn - store.hcm@rpc.vn Học PIC như thế nào? |
|
|
|
|
22-03-2006, 04:06 PM
|
#13 |
|
Đệ tử 9 túi

Tham gia ngày: Jul 2005
Nơi Cư Ngụ: Grenoble - FRANCE
Bài gửi: 38
: |
Bộ lọc Kalman có thể tham khảo một cách đơn giản hơn với tài liệu này:
http://www.cs.unc.edu/~welch/kalman/index.html http://www.cs.unc.edu/~welch/media/pdf/kalman_intro.pdf Tui đã dịch sang tiếng Việt bộ lọc Kalman, xin hẹn gửi cho quý vị vào cuối tuần này. Ngoại ra, có thể tham khảo source code bô lọc Kalman áp dụng cho PIC trong báo cáo luận văn Mr.Scooter. Chào cả nhà.
__________________
 Không béo bề ngang thì cũng bổ bề dọc Không béo bề ngang thì cũng bổ bề dọcKhông bổ cho ruột non thì cũng bổ ruột ... |
|
|
|
|
22-03-2006, 07:49 PM
|
#14 |
|
Đệ tử 9 túi
Tham gia ngày: Jul 2005
Nơi Cư Ngụ: Grenoble - FRANCE
Bài gửi: 38
: |
Theo ý kiến của mình, xin đổi một tí trong bài của falleaf như sau:
Bài 4: Nhiễu : gồm 2 loại là nhiễu tiến trình và nhiễu đo. Falleaf mới nói nhiễu đo, chưa đề cập nhiễu tiến trình. Đo tương quan của nhiễu tiến trình lại khó hơn nhiều so với nhiễu đo (bời thong số nhiễu đo có trên cảm biến). Ngoài ra có một dạng nữa là nhiễu đo trong tiến trình, noí cách khác nhiễu này chĩ xảy ra khi áp dụng cảm biến vào toàn bộ hệ thống, chứ caliber đơn cảm biến sẽ không nhận ra được. 4.8 Và F có một cái câu rất hay nói ngoài miệng khi quyết định một cái chuyện gì đó rằng: "Xác suất chỉ có ý nghĩa khi nó tiến ra vô cùng" : không chính xác vì nếu chọn một lượng mẫu phù hợp cho một đại lượng phụ hợp với một độ chính xác chấp nhận được (80% hay 95%), ta vẫn có thể xác định được chứ không cần phải tiến ra vô cùng.
__________________
Không béo bề ngang thì cũng bổ bề dọcKhông bổ cho ruột non thì cũng bổ ruột ... |
|
|
|
|
24-06-2006, 05:28 PM
|
#15 | |
|
Đệ tử 1 túi

Tham gia ngày: Jun 2006
Bài gửi: 12
: |
Trích:
Falleaf "nói oan" cho bộ lọc Kalman rồi; lọc Kalman chỉ tìm ra trạng thái ước lượng của hệ thôi. Nói như bạn, hóa ra dùng bộ lọc Kalman, ta có thể tìm được mô hình của đối tượng à??? Nếu (A, B, C, D) là biểu diễn trạng thái của hệ, thì ta cần phải biết ma trận A, C mới thiết kế bộ lọc Kalman được chứ. Trong điều khiển tối ưu, bộ lọc Kalman chính là bộ ước lượng trạng thái tối ưu (hay bộ quan sát trạng thái tối ưu). Mục tiêu của bộ quan sát là tìm vectơ trạng thái ước lượng sao x^ sao cho x^ bám theo x (x là vector trạng thái "thật"). Tại sao phải dùng bộ quan sát trạng thái? Trong thiết kế bộ điều khiển phản hồi trạng thái u = -Kx, ban đầu người ta có giả thiết là tất cả các trạng thái đều đo được; sau đó dùng các phương pháp thiết kế (pole placement, LQR,...) để tìm ra K. Nhưng thực tế thường không dễ dàng đo được tất cả các trạng thái vì ko có đủ cảm biến, hơn nữa có thể có những trạng thái ko có ý nghĩa vật lý. Vì thế, người ta dùng bộ quan sát trạng thái, để từ đầu vào (u) đầu ra (y) của đối tượng, ta có thể ước lượng được những trạng thái không đo được. Tóm lại, đầu vào của bộ quan sát là u, y; đầu ra là x^ (ước lượng của x). Ta thấy bài toán thiết kế bộ quan sát tương tự như bài toán thiết kế bộ điều khiển hồi tiếp trạng thái. - Thiết kế bộ điều khiển: tìm ma trận K sao cho y bám theo y_đặt. - Thiết kế bộ quan sát: tìm ma trận L sao cho x^ bám theo x. Đây là 2 bài toán có tính đối ngẫu (duality). Trong MATLAB nếu dùng 'place' để thiết kế bộ điều khiển thì ta cũng có thể dùng 'place' để thiết kế bộ quan sát bằng cách thay đổi tham số vào: A thay bằng A' (A chuyển vị), B thay bằng C'.Bằng cách chỉ định cực của bộ quan sát, ta có thể thay đổi cách x^ bám theo x như ý muốn. Trong trường hợp này ta có bộ quan sát Luenberger. Trong trường hợp thiết kế bộ điều khiển tối ưu LQR, ta tìm K tối ưu cực tiểu hóa phiếm hàm J bằng cách giải 1 phương trình Riccati. Thông số thiết kế trong bài toán LQR là ma trận trọng số Q, R (xem tài liệu về LQR để biết cụ thể). Tương tự như vậy, nếu ta tìm được L tối ưu bằng cách giải 1 phương trình Riccati tương tự phương trình Riccati trên, thì ta sẽ được bộ quan sát trạng thái tối ưu. Đây chính là bộ lọc Kalman . "Thông số thiết kế" (tạm gọi như vậy) trong trường hợp này là W, V (covariance của nhiễu ngẫu nhiên). Trong MATLAB, nếu dùng hàm 'lqr' để thiết kế bộ điều khiển tối ưu LQR, thì ta cũng có thể dùng 'lqr' để thiết kế bộ lọc Kalman bằng cách thay A bằng A', B bằng C', Q bằng W, R bằng V. Nói thêm, LQR + bộ lọc Kalman = LQG (Linear Quadratic Gaussian). Cụ thể thế nào thì các bạn tìm tài liệu đọc thêm. Ghi chú: bộ quan sát trạng thái = bộ ước lượng trạng thái = bộ quan sát (nói tắt) = bộ ước lượng (nói tắt). Keywords: Optimal control, LQR (Linear Quadratic Regulator), LQG (Linear Quadratic Gaussian), state feedback control, state observer, state estimator, Kalman filter, Luenberger filter. thay đổi nội dung bởi: benq, 24-06-2006 lúc 07:48 PM. |
|
|
|
|
|
|
|
 Similar Threads
Similar Threads
|
||||
| Ðề tài | Người gửi | Chuyên mục | Trả lời | Bài mới |
| Bộ lọc Kalman dùng PIC | falleaf | RTOS và Thuật toán với PIC | 19 | 30-01-2014 08:19 PM |
| Kalman filter: tutorial function | ami | Matlab-Simulink & Labview & 20-Sim | 0 | 30-03-2006 10:58 PM |

 falleaf
falleaf
 ami
ami Linear Mode
Linear Mode

